
字符串算法与哈希技巧
By Niolle
Hash
Hash 定义
我们定义一个把字符串映射到整数的函数
性质
具体来说,哈希函数最重要的性质可以概括为下面两条:
在 Hash 函数值不一样的时候,两个字符串一定不一样; 在 Hash 函数值一样的时候,两个字符串不一定一样(但有大概率一样,且我们当然希望它们总是一样的)。 我们将 Hash 函数值一样但原字符串不一样的现象称为哈希冲突。
基本形式
通常我们采用的是多项式 Hash 的方法,对于一个长度为 l 的字符串
例如,对于字符串
其中M为哈希模数,我们习惯取一个大质数,如
Hash Code
int M = 1e9 + 7;
int B = 233;
using ll = long long;
int get_hash(string s) {
int res = 0;
for (int i = 0; i < s.size(); ++i) {
res = (1ll * res * B + s[i]) % M; //过程中会超出int范围,故×1ll
}
return res;
}
bool cmp(string s,string t) {
return get_hash(s) == get_hash(t);
}处理哈希冲突
多值哈希
多值 Hash,就是有多个 Hash 函数,每个 Hash 函数的模数不一样,这样就能解决 Hash 冲突的问题。
判断时只要有其中一个的 Hash 值不同,就认为两个字符串不同,若 Hash 值都相同,则认为两个字符串相同。
一般来说,双值 Hash 就够用了。
双值Hash Code
int M = 1e9 + 7, m = 998244353;
int B = 233;
using ll = long long;
int get_hash1(string s) {
int res = 0;
for (int i = 0; i < s.size(); ++i) {
res = (1ll * res * B + s[i]) % M; //过程中会超出int范围,故 × 1ll
}
return res;
}
int get_hash2(string s) {
int res = 0;
for (int i = 0; i < s.size(); ++i) {
res = (1ll * res * B + s[i]) % m; //过程中会超出int范围,故 × 1ll
}
return res;
}
bool cmp(string s,string t) {
if(get_hash1(s) != get_hash1(t)) return 0;
if(get_hash2(s) != get_hash2(t)) return 0;
return 1;
}处理哈希冲突
大模数哈希
- 依据1e9级别模数冲突原理——生日攻击理论,比较次数只要达到 级别就有超过50%的概率发生crash.这种写法被卡掉的根本原因是概率不对. 采取1e18级别的质数作为模数即可,如
注意乘法过程中要开 __int128
luogu P3370 【模板】字符串哈希
如题,给定 N 个字符串(第 i 个字符串长度为
对于
题解
- 模板题,对于每个字符串求出他的哈希值,再
暴力比较即可
luogu P3805 【模板】manacher
给出一个只由小写英文字符
对于
题解
马拉车板子,但是也有个很经典的哈希做法,即二分+Hash 如何判断字符串是否是哈希呢?只需要某个区间正着的Hash值和反着的Hash值相同
//判断是否为回文串
bool check(string s) {
string t = ReverseString(s); //t是s的翻转串
return get_hash(s) == get_hash(t);
}通常需要判断的是某个区间是否为回文串,使用substr()再跑hash会很慢,这里介绍使用前缀和作差得到区间Hash值的方法
设
判断一个区间是否为回文串可以使用这个区间正着的Hash值是否等于这个区间反着的Hash着来判断
这个区间反着的Hash值具体求法为,设rhash[i]表示字符串S后i个字符的Hash值,
回到原问题,如何找到最长的最长回文串
直接枚举子区间判断是否为回文串可做到O(n^2)的复杂度 二分的解法为,先枚举对称中心,然后二分每个对称中心的最长回文串长度,这个是存在单调性的,即若区间
时间复杂度:
KMP
border定义
border :若字符串
前缀函数定义
给定一个长度为 n 的字符串 s,其 前缀函数 被定义为一个长度为 n 的数组
1.如果子串
前缀函数求解过程
过程 举例来说,对于字符串 abcabcd,
同理可以计算字符串 aabaaab 的前缀函数为 [0, 1, 0, 1, 2, 2, 3]。
计算前缀函数的朴素做法
一个直接按照定义计算前缀函数的算法流程:
在一个循环中以
第一个优化
第一个重要的观察是 相邻的前缀函数值至多增加 1。
参照下图所示,只需如此考虑:当取一个尽可能大的
Code
vector<int> prefix_function(string s) {
int n = (int)s.length();
vector<int> pi(n);
for (int i = 1; i < n; i++)
for (int j = pi[i - 1] + 1; j >= 0; j--) // improved: j=i => j=pi[i-1]+1
if (s.substr(0, j) == s.substr(i - j + 1, j)) {
pi[i] = j;
break;
}
return pi;
}第二个优化
在第一个优化中,我们讨论了计算
KMP Code
显然我们可以得到一个关于 j 的状态转移方程:
结合上述的两个优化,可以得到时间复杂度为
vector<int> prefix_function(string s) {
int n = (int)s.length();
vector<int> pi(n);
for (int i = 1; i < n; i++) {
int j = pi[i - 1];
while (j > 0 && s[i] != s[j]) j = pi[j - 1];
if (s[i] == s[j]) j++;
pi[i] = j;
}
return pi;
}border性质
border :若字符串
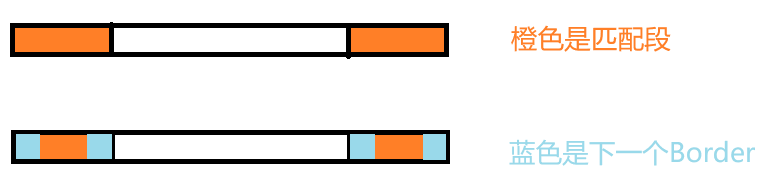
- 性质1:对于任意一个字符串S,一个Border的长度就对应一个Border(比如abcdabc的长度为3的Border当然就只能是abc)。并且,假设S长度记为n,则S的则S所有Border长度分别为:
- 性质2:根据该结论,求出
函数即可得到整个字符串的所有border
性质图示
在字符串中查找子串(luogu KMP模板题)
给定一个文本
为了简便起见,我们用 n 表示字符串 s 的长度,用 m 表示文本 t 的长度。
我们构造一个字符串
Code
vector<int> find_occurrences(string text, string pattern) {
string cur = pattern + '#' + text;
int sz1 = text.size(), sz2 = pattern.size();
vector<int> v;
vector<int> lps = prefix_function(cur);
for (int i = sz2 + 1; i <= sz1 + sz2; i++) {
if (lps[i] == sz2) v.push_back(i - 2 * sz2);
}
return v;
}字符串的周期
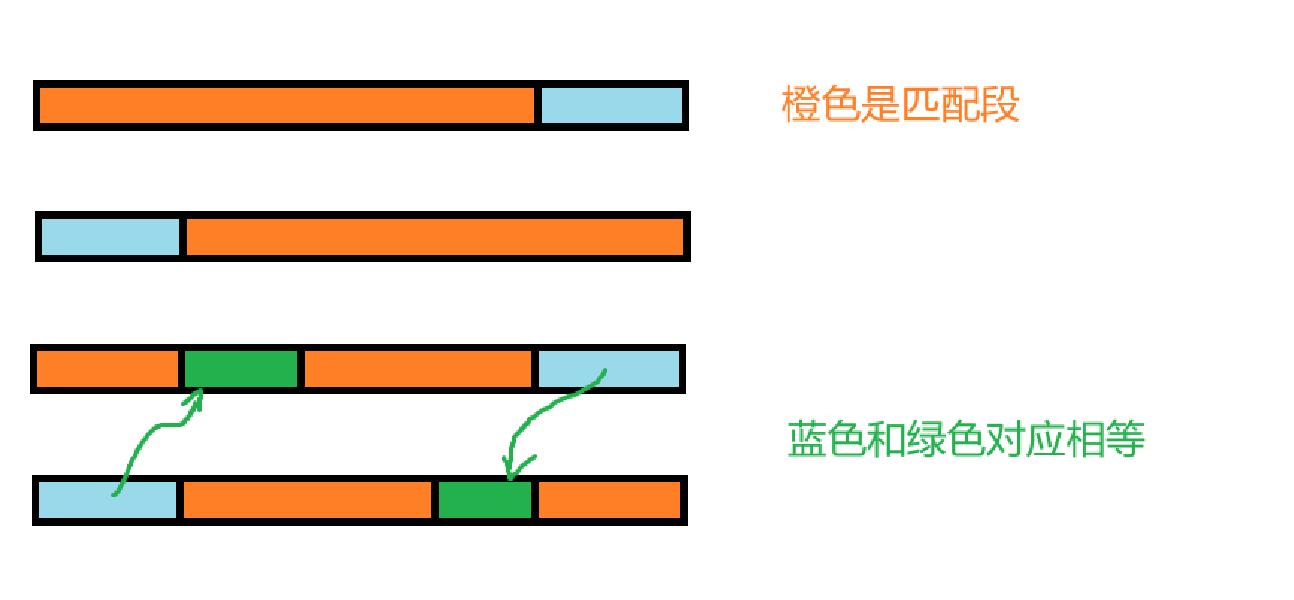
对字符串
对字符串
由 s 有长度为 r 的 border 可以推导出
根据前缀函数的定义,可以得到 s 所有的 border 长度,即
所以根据前缀函数可以在 O(n) 的时间内计算出 s 所有的周期。其中,由于 \pi[n-1] 是 s 最长 border 的长度,所以
图示
统计每个前缀的出现次数
给定一个长度为 n 的字符串 s,我们希望统计每个前缀
首先让我们来解决第一个问题。考虑位置
Code
vector<int> ans(n + 1);
for (int i = 0; i < n; i++) ans[pi[i]]++;
for (int i = n - 1; i > 0; i--) ans[pi[i - 1]] += ans[i];
for (int i = 0; i <= n; i++) ans[i]++;一个字符串中本质不同子串的数目
给定一个长度为 n 的字符串 s,我们希望计算其本质不同子串的数目。
我们将迭代的解决该问题。换句话说,在知道了当前的本质不同子串的数目的情况下,我们要找出一种在 s 末尾添加一个字符后重新计算该数目的方法。
令 k 为当前 s 的本质不同子串数量。我们添加一个新的字符 c 至 s。显然,会有一些新的子串以字符 c 结尾。我们希望对这些以该字符结尾且我们之前未曾遇到的子串计数。
构造字符串
因此,当添加了一个新字符后新出现的子串数目为
推荐习题
字符串的第一章和第二章